前言
前面写过一篇深度学习生成 HTML 探索之 pix2code(论文),主要是记录一下自己对《pix2code: Generating Code from a Graphical User Interface Screenshot》这篇论文的理解。但是文章最后对于模型的训练以及实际效果并没有做相应的实验,所以今天借着这个机会,来补充一下相关实践,毕竟实践出真知嘛!
pix2code
首先我们来看看 pix2code 模型,这个模型如何运行在其 github 上的README.md文件中写得很清楚了,首先把项目 clone 到本地,clone 下来之后的项目目录如下图所示:
图中的 requirements.txt 文件中是整个项目所需要的依赖包,可以直接用pip命令安装:
pip install -r requirements.txt但是小编在安装的时候出现了一些问题,例如有些安装包找不到对应的版本,如下图所示,那小编采用的办法就是一个一个的安装依赖包,找不到对应版本的依赖包就选择一个较为接近的版本安装。
安装完依赖包之后,就可以运行模型啦~
从 github 上 clone 下来的代码是没有模型的权重文件的,所以需要利用数据进行训练后生成权重模型,可以直接利用已有的训练数据,命令如下所示。可以看到重组解压之后的数据分为 IOS、Android 和 Web 三种数据。
# 进入数据集文件夹
cd datasets
# 重组解压数据
zip -F pix2code_datasets.zip --out datasets.zip
unzip datasets.zip笔者用的是 win10 系统,无法直接用 zip 命令。所以需要在 widows 上安装 zip 命令,笔者采用的是安装 GnuWin32,方法很简单:
- GnuWin32 官网下载安装包安装之后一路 next 安装(可以自定义安装目录)
- 安装完成后将 bin 目录添加到环境变量即可
获得数据之后,还需要将数据切割成训练集和验证集:
cd ../model
# 切割训练集和验证集,确保不会有训练样本混入验证集,默认训练集比例是60%
# 用法: build_datasets.py <input path> <distribution (default: 6)>
./build_datasets.py ../datasets/ios/all_data
./build_datasets.py ../datasets/android/all_data
./build_datasets.py ../datasets/web/all_data将训练集中的图片转换为 numpy 数组可减小数据大小,方便上传云端保存。
# 用法: convert_imgs_to_arrays.py <input path> <output path>
./convert_imgs_to_arrays.py ../datasets/ios/training_set ../datasets/ios/training_features
./convert_imgs_to_arrays.py ../datasets/android/training_set ../datasets/android/training_features
./convert_imgs_to_arrays.py ../datasets/web/training_set ../datasets/web/training_features在根目录下新建一个 bin 文件夹用于存放模型数据:
mkdir bin
cd model
# 用法: train.py <input path> <output path> <is memory intensive (default: 0)> <pretrained weights (optional)>
./train.py ../datasets/web/training_set ../bin
# 训练预处理之后的图片
./train.py ../datasets/web/training_features ../bin
# 避免将所有数据送入内存(推荐)
./train.py ../datasets/web/training_features ../bin 1
# 如果有预训练模型权重,可以在其基础上进行训练
./train.py ../datasets/web/training_features ../bin 1 ../bin/pix2code.h5新建一个 code 文件夹用于保存测试数据,测试图片如下图。
- 生成 DSL 代码(.gui 文件):
mkdir code
cd model
# 用法: sample.py <trained weights path> <trained model name> <input image> <output path> <search method (default: greedy)>
./sample.py ../bin pix2code ../test.png ../code
# equivalent to command above
./sample.py ../bin pix2code ../test.png ../code greedy
# generate DSL code with beam search and a beam width of size 3
./sample.py ../bin pix2code ../test.png ../code 3- 将生成的代码编译成目标语言:
cd compiler
# Android XML UI
./android-compiler.py <input file path>.gui
# iOS Storyboard
./ios-compiler.py <input file path>.gui
# HTML/CSS (Bootstrap style)
./web-compiler.py <input file path>.gui- 结果:
- .gui 文件:
<START> header { btn-inactive , btn-inactive } row { quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } } row { quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } } row { quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } } row { quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } quadruple { small-title , text , btn-orange } } row { quadruple {- html 文件在浏览器中打开如下:
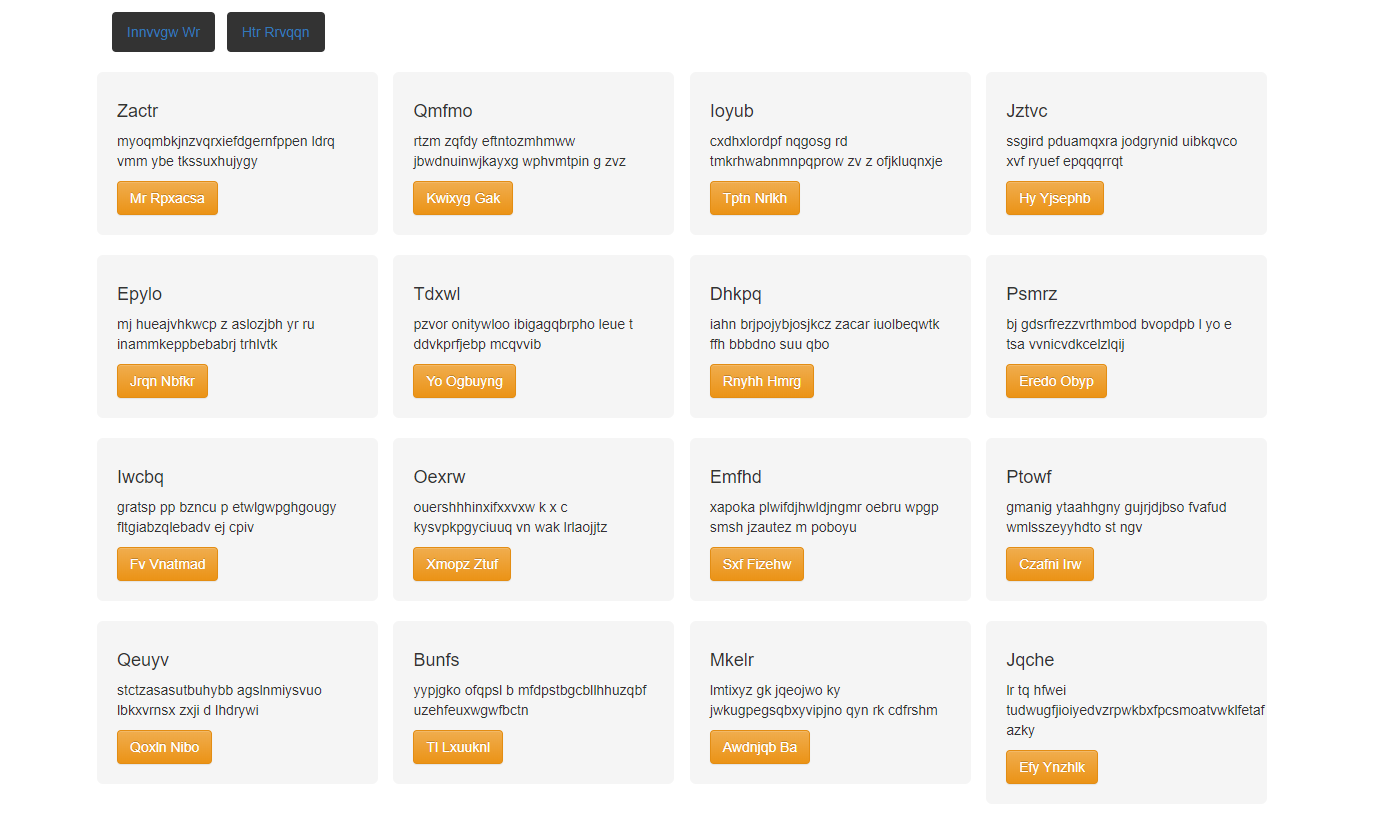
总结
能看出来模型的准确率还是有待提高,可能是训练数据不够导致的,总之结果不是特别令人满意。IOS 和 Android 图片还未做实验,不过笔者曾在 github 上看到一个项目貌似效果还不错,网上还有其翻译文章,不过该项目使用.ipynb 文件实现的,笔者电脑上环境还有点问题,待解决之后再看吧,项目地址和相关文章我贴在下面,感兴趣的同学可以去康康~

