前言
最近做的几个需求都是和表单相关,需要涉及到一些输入规则校验,笔者本身对这一块不是特别熟悉,所以借这个机会结合网上的一些资料,对 JavaScript 正则表达式做一次完整的梳理。
正则表达式(Regular expression)是一组由字母和符号组成的特殊文本, 它可以用来从文本中找出满足你想要的格式的句子。正则表达式的本质是匹配模式,要么匹配字符,要么匹配位置。
可视化工具:
正则表达式是绝大部分编程语言中的内建模块,是有必要掌握的基础知识。有的同学对正则表达式不熟悉,只会写简单的正则,稍微复杂一点的只能靠复制粘贴,这样很难保证正则表达式的正确性。在遇到需要维护的复杂正则的时候,也可能因为看不懂而无从下手。
正则表达式的字符匹配
模糊匹配
如果正则只有精确匹配是没多大意义的,比如 /hello/,也只能匹配字符串中的 “hello” 这个子串。而正则表达式的强大则在于它的模糊匹配,这里介绍两个方向上的“模糊”:横向模糊和纵向模糊。
横向模糊
横向模糊指的是,一个正则可匹配的字符串的长度不是固定的,可以是多种情况的。其实现的方式是使用量词。譬如 {m,n},表示连续出现最少 m 次,最多 n 次。
例如:
/ab{2,5}c/g,其可视化形式为: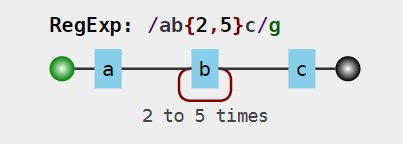
代码测试:
const regex = /ab{2,5}c/g; const string = "abc abbc abbbc abbbbc abbbbbc abbbbbbc"; console.log(string.match(regex)); // => ["abbc", "abbbc", "abbbbc", "abbbbbc"]纵向模糊
纵向模糊指的是,一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符,可以有多种可能。其实现的方式是使用字符组。譬如 [abc],表示该字符是可以字符 “a”、”b”、”c” 中的任何一个。
例如:
/a[123]b/,其可视化形式为:![/a[123]b/可视化](https://i.loli.net/2019/12/26/3R4Qmu8paLIewGo.png)
代码测试:
const regex = /a[123]b/g; const string = "a0b a1b a2b a3b a4b"; console.log(string.match(regex)); // => ["a1b", "a2b", "a3b"]
字符组
字符组表示匹配组内的一个字符。例如:[abc],匹配 “a”、”b”、”c” 其中之一。
范围表示法
当字符组中的字符较多的时候,可以用范围表示法来表示一定范围内的匹配字符。也就是用**连字符-**来进行省略和简写。例如:
[56789ABCDEFG]可以用[5-9A-G]来表示。注意:如果要匹配的连字符中包含**连字符-**的话,需要注意连字符即要么放在表达式开头,要么放在结尾,要么转义。总之不要让引擎认为是范围表示法。
排除字符组
纵向模糊匹配,还有一种情形就是,某位字符可以是任何东西,但就不能是 “a”、”b”、”c”。这个时候就需要用到排除字符组,即将 ^(脱字符)放在字符组的第一位,表示求反的意思。例如:例如
[^abc],表示的是一个除 “a”、”b”、”c”之外的任意一个字符。常见简写
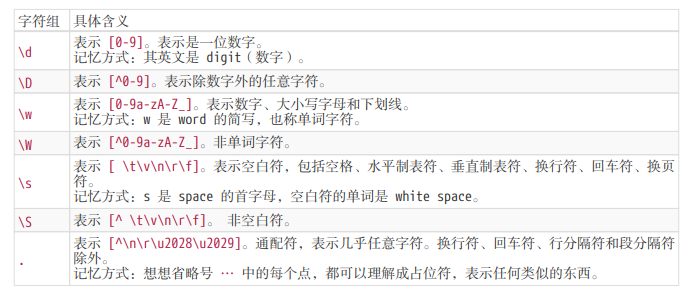
如何匹配任意字符?可以使用 [\d\D]、[\w\W]、[\s\S] 和 [^] 中任何的一个。
以上各字符组对应的可视化形式:
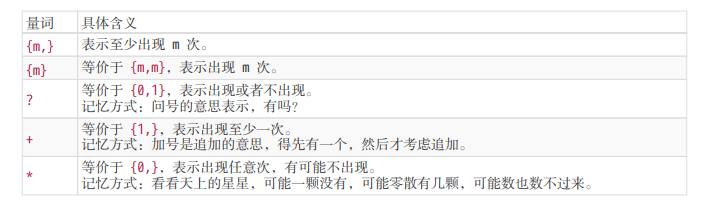
量词
量词也称重复。在掌握 {m,n} 的准确含义后,只需要记住一些简写形式。
上述量词对应的可视化形式为:

贪婪匹配与惰性匹配
- 贪婪匹配。例如:
/\d{3,7}/,会尽可能多匹配,有 4 个就匹配 4 个,有 3 个就匹配 3 个。 - 惰性匹配。例如:
/\d{3,7}?/,会尽可能少匹配,有 3 个匹配后就不再继续。
代码测试:
const r1 = /\d{3,7}/g; const r2 = /\d{3,7}?/g; const testString = "123 1234 12 12345 1 123456"; console.log(testString.match(r1)); //[ '123', '1234', '12345', '123456' ] console.log(testString.match(r2)); //[ '123', '123', '123', '123', '456' ]通过在量词后面加个问号就能实现惰性匹配,因此所有惰性匹配情形如下:
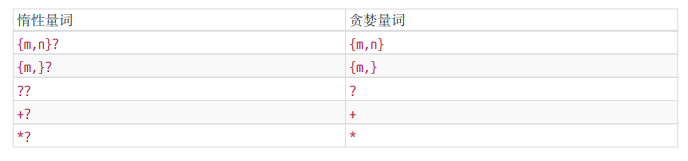
- 贪婪匹配。例如:
多选分支
一个模式可以实现横向和纵向模糊匹配,而多选分支可以支持多个子模式任选其一。但是分支结构是惰性的。
语法:(p1|p2|p3),其中 p1、p2 和 p3 是子模式,用 |(管道符)分隔,表示其中任何之一。
例如:表达式/hello|world/的可视化形式为: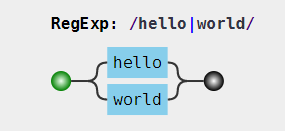
惰性分支的惰性表现*(当前面的分支匹配上了,后面的分支就不再尝试了)*:// 多选分支的惰性表现 const r1 = /biubiu|biubiuuu/g; const r2 = /biubiuuu|biubiu/g; const testString = "biubiuuu"; console.log(testString.match(r1)); //[ 'biubiu' ] console.log(testString.match(r2)); //[ 'biubiuuu' ]案例分析
要求:从代码
<div id="container" class="main"></div>中提取出id="container"//尝试一: const r = /id=".*"/; const string = '<div id="container" class="main"></div>'; console.log(string.match(r)[0]); //id="container" class="main"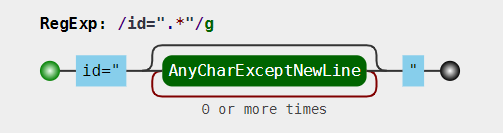
因为 . 是通配符,本身就匹配双引号的,而量词 * 又是贪婪的,会尽可能多的匹配,所以当遇到 *container* 后面双引号时,不会停下来而是会继续匹配,直到遇到最后一个双引号为止。使用惰性匹配,可以达到目的但效率低,有回溯问题。
//尝试二: const r = /id=".*?"/; const string = '<div id="container" class="main"></div>'; console.log(string.match(r)[0]); //id="container"优化如下,通过使用^(脱字符)来保证两个双引号中间不会出现第三个双引号:
//尝试三: const r = /id="[^"]*"/; const string = '<div id="container" class="main"></div>'; console.log(string.match(r)[0]); //id="container"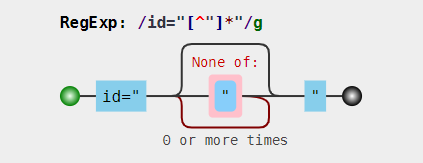
正则表达式的位置匹配
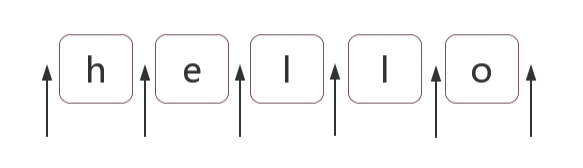
什么是位置?
位置(锚)是相邻字符之间的位置。比如,下图中箭头所指的地方:
如何匹配位置?
在 ES5 中,共有 6 个锚:^、$、\b、\B、(?=p)、(?!p),则相应的可视化形式为:

^ 和 $
^(脱字符)匹配开头,在多行匹配中匹配行开头。
$(美元符号)匹配结尾,在多行匹配中匹配行结尾。//单行匹配 const result1 = "hello".replace(/^|$/g, "🤣"); console.log(result1); //🤣hello🤣 //多行匹配 const result2 = "hello\nworld".replace(/^|$/gm, "🤣"); console.log(result2); /* * 🤣hello🤣 * 🤣world🤣 */\b 和 \B
\b 是单词边界,具体就是 \w 与 \W 之间的位置,也包括 \w 与 ^ 之间的位置,和 \w 与 $ 之间的位置。
\B 就是 \b 的反面的意思,非单词边界。在字符串中所有位置中,扣掉 \b,剩下的都是 \B 的。具体说来就是 \w 与 \w、 \W 与 \W、^ 与 \W,\W 与 $ 之间的位置。// \b const result1 = "[JS] Lesson_01.mp4".replace(/\b/g, "😍"); console.log(result1); //[😍JS😍] 😍Lesson_01😍.😍mp4😍 // \B const result2 = "[JS] Lesson_01.mp4".replace(/\B/g, "😍"); console.log(result2); //😍[J😍S]😍 L😍e😍s😍s😍o😍n😍_😍0😍1.m😍p😍4(?=p) 和 (?!p)
二者的学名分别是 positive lookahead 和 negative lookahead。中文翻译分别是正向先行断言和负向先行断言。(?=p),其中 p 是一个子模式,即 p 前面的位置,或者说,该位置后面的字符要匹配 p。而 (?!p) 就是 (?=p) 的反面意思。
// (?=p) // (?=l) 表示 l 字符前面的位置 const result1 = "hello".replace(/(?=l)/g, "😊"); console.log(result1); // => he😊l😊lo // (?!p) // (?!l) 表示不是 l 字符的字符前面的位置 const result2 = "hello".replace(/(?!l)/g, "😊"); console.log(result2); // => 😊h😊ell😊o😊ES5 之后的版本,会支持 (?<=p) 和 (?<!p)。(?<=p) 表示 p 后面的位置,而 (?<!p) 表示的意思则与其相反。
// (?<=p) // (?<=l) 表示 l 字符后面的位置 const result1 = "hello".replace(/(?<=l)/g, "😉"); console.log(result1); // => hel😉l😉o // (?<!p) // (?<!l) 表示不是 l 字符的字符后面的位置 const result2 = "hello".replace(/(?<!l)/g, "😉"); console.log(result2); // => 😉h😉e😉llo😉
位置的特性
我们可以将位置理解成空字符””。也就是说字符之间的位置,可以写成多个。例如:把
/^hello$/写成/^^hello$$$/是完全没有问题的。// /^hello$/ const result1 = /^hello$/.test("hello"); console.log(result1); // true // /^^hello$$$/ const result2 = /^^hello$$$/.test("hello"); console.log(result2); // true案例分析
- 不匹配任何东西的正则:/.^/
- 验证密码的问题:密码长度 6-16 位,由数字、小写字符和大写字母组成,但必须至少包括 2 种字符。
第一步:简化版(不考虑”但必须至少包括 2 种字符”这一条件)const regex = /^[0-9A-Za-z]{6,16}$/;
第二步:判断是否包含有某一种字符(假设是数字)const regex = /(?=.*[0-9])^[0-9A-Za-z]{6,16}\$/; //利用正向先行断言
第三步:同时包含两种字符(比如同时包含数字和小写字母,可以用(?=.*[0-9])(?=.*[a-z])来做)const regex = /(?=.*[0-9])(?=.*[a-z])^[0-9A-Za-z]{6,16}$/;
第四步:拆分需求情况:- 同时包含数字和小写字母
const regex = /(?=.*[0-9])(?=.*[a-z])^[0-9A-Za-z]{6,16}$/; - 同时包含数字和大写字母
const regex = /(?=.*[0-9])(?=.*[A-Z])^[0-9A-Za-z]{6,16}$/; - 同时包含小写字母和大写字母
const regex = /(?=.*[A-Z])(?=.*[a-z])^[0-9A-Za-z]{6,16}$/; - 同时包含数字、小写字母和大写字母
const regex=/(?=.*[A-Z])(?=.*[a-z])(?=.*[0-9])^[0-9A-Za-z]{6,16}$/; - 以上的 4 种情况是或的关系(实际上,可以不用第 4 条)。
所以,最终答案是:
可视化形式:// 密码验证 const regex = /((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[A-Z]))^[0-9A-Za-z]{6,16}$/; console.log(regex.test("467664")); // false 全是数字 console.log(regex.test("fgjghjh")); // false 全是小写字母 console.log(regex.test("GJKHIKJL")); // false 全是大写字母 console.log(regex.test("hl23C")); // false 不足6位 console.log(regex.test("hl23C6+6+sdfs")); // false 有其他字符 console.log(regex.test("hl23C66GGHsdfs556")); // false 长度超过16位 console.log(regex.test("HJJYUU234")); // true 大写字母和数字 console.log(regex.test("abcdEF234")); // true 三者都有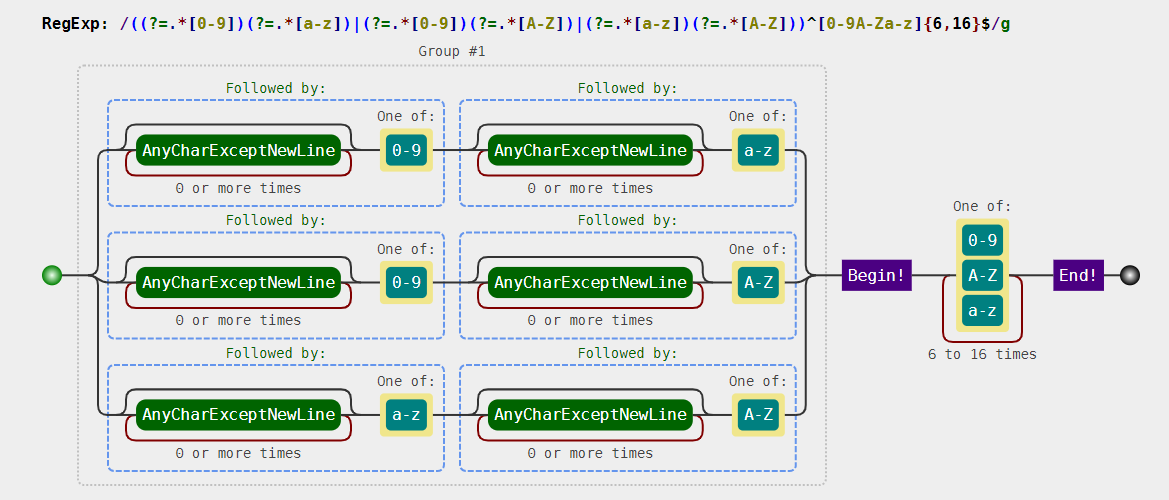
- 同时包含数字和小写字母
- 解读:
上述正则只要弄懂第二步,其余步骤就可以理解了,也就是说我们只需要弄明白(?=.*[0-9])^即可。(?=.*[0-9])^分开来看就是(?=.*[0-9])和^。表示开头前面还有个位置(当然也是开头,即同一个位置,和之前的空字符是同一个道理)。(?=.*[0-9])表示该位置后面的字符匹配.*[0-9],即,有任何多个任意字符,后面再跟个数字。翻译成大白话,就是接下来的字符,必须包含个数字。 - 另一种解法:“至少包含两种字符”的意思就是说,不能全部都是数字,也不能全部都是小写字母,也不能全部都是大写字母。
利用(?!p)
最终答案:const regex = /(?!^[0-9]{6,16}$)(?!^[a-z]{6,16}$)(?!^[A-Z]{6,16}$)^[0-9A-Za-z]{6,16}$/;
正则表达式括号的作用
分组和分支结构
分组和分支结构是括号最直接的作用,也是最原始的功能,强调括号内的正则是一个整体,即提供子表达式。
- 分组,强调括号内的是一个整体
// 分组 const regex = /(ab)+/g; const string = "ababa abbb ababab"; console.log(string.match(regex)); // [ 'abab', 'ab', 'ababab' ] const regex1 = /ab+/g; console.log(string.match(regex1)); //[ 'ab', 'ab', 'abbb', 'ab', 'ab', 'ab' ]- 分支结构,在多选分支结构 (p1|p2) 中,此处括号的作用提供了分支表达式的所有可能。
例如/^I love (JavaScript|Regular Expression)$/和/^I love JavaScript|Regular Expression$/这两个分支的可视化分别为: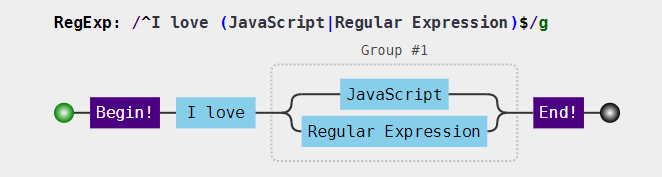

分组引用
分组引用是括号的另一个重要作用,有了它,我们就可以进行数据提取,以及更强大的替换操作。
以日期为例。假设格式是 yyyy-mm-dd 的,我们可以先写一个简单的正则:const regex = /\d{4}-\d{2}-\d{2}/;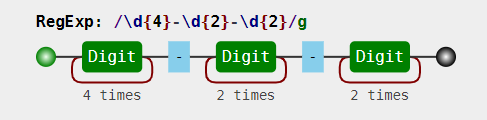
给正则表达式加上括号:const regex = /(\d{4})-(\d{2})-(\d{2})/;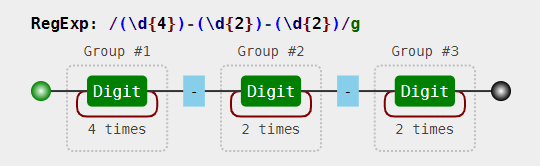
可以看到加了括号之后,多了分组编号,如 Group #1。其实正则引擎也是这么做的,在匹配过程中,给每一个分组都开辟一个空间,用来存储每一个分组匹配到的数据。
使用分组捕获的数据:提取数据
比如提取出年、月、日:
返回的一个数组,第一个元素是整体匹配结果,然后是各个分组(括号里)匹配的内容,然后是匹配下标,最后是输入的文本。另外,正则表达式是否有修饰符 g,match 返回的数组格式是不一样的。// 提取数据 const regex = /(\d{4})-(\d{2})-(\d{2})/; const string = "2019-12-31"; console.log(string.match(regex)); // ['2019-12-31','2019','12','31',index: 0,input: '2019-12-31',groups: undefined]替换数据
比如把 yyyy-mm-dd 格式,替换成 mm/dd/yyyy:
其中 replace 中的,第二个参数里用 $1、$2、$3 指代相应的分组。等价于:// 替换数据 const regex = /(\d{4})-(\d{2})-(\d{2})/; const string = "2019-12-31"; const result = string.replace(regex, "$2/$3/$1"); console.log(result); // 12/31/2019const regex = /(\d{4})-(\d{2})-(\d{2})/; const string = "2019-12-31"; const result = string.replace(regex, function(match, year, month, day) { return month + "/" + day + "/" + year; }); console.log(result); // 12/31/2019
反向引用
除了使用相应 API 来引用分组,也可以在正则本身里引用分组。但只能引用之前出现的分组,即反向引用。可以使用 \n 来匹配捕获到的第 n 个分组。
例如:写一个匹配 2019-11-25 或 2019.11.25 或 2019/11/25 这三种格式日期的正则。// 常见,无法保证分隔符前后一致 const regex = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/; const string1 = "2019-12-31"; const string2 = "2019/12/31"; const string3 = "2019.12.31"; const string4 = "2019-12/31"; console.log(regex.test(string1)); // true console.log(regex.test(string2)); // true console.log(regex.test(string3)); // true console.log(regex.test(string4)); // true // 反向引用 const regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/; const string1 = "2019-12-31"; const string2 = "2019/12/31"; const string3 = "2019.12.31"; const string4 = "2019-12/31"; console.log(regex.test(string1)); // true console.log(regex.test(string2)); // true console.log(regex.test(string3)); // true console.log(regex.test(string4)); // false反向引用可视化形式:
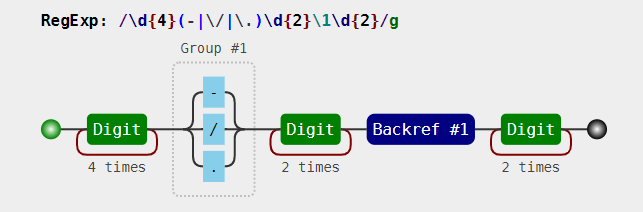
表达式里面的 \1,表示的引用之前的那个分组(-|\/|\.)。不管它匹配到什么(比如 -),\1 都匹配那个同样的具体某个字符。同理可得,那么 \2 和 \3 的概念也就理解了,即分别指代第二个和第三个分组。- 括号嵌套,以左括号(开括号)为准。
const regex = /^((\d)(\d(\d)))\1\2\3\4$/; const string = "1231231233"; console.log(regex.test(string)); // true console.log(RegExp.$1); // 123 console.log(RegExp.$2); // 1 console.log(RegExp.$3); // 23 console.log(RegExp.$4); // 3- \10 表示第 10 个分组
const regex = /(1)(2)(3)(4)(5)(6)(7)(8)(9)(#) \10+/; const string = "123456789# 99999"; const string1 = "123456789# ####"; console.log(regex.test(string)); // => false console.log(regex.test(string1)); // => true- 分组后面有量词时,分组最终捕获到的数据是最后一次的匹配。
const regex = /(\d)+ \1/; console.log(regex.test("12345 1")); // => false console.log(regex.test("12345 5")); // => true非捕获括号
之前文中出现的括号,都会捕获它们匹配到的数据,以便后续引用,因此也称它们是捕获型分组和捕获型分支。
如果只想要括号最原始的功能,但不会引用它,即,既不在 API 里引用,也不在正则里反向引用。 此时可以使用非捕获括号 (?:p)和 (?:p1|p2|p3)。案例分析
- 驼峰化
其中分组 (.) 表示首字母。单词的界定是,前面的字符可以是多个连字符、下划线以及空白符。正则后面的 ? 的目的,是为了应对 str 尾部的字符可能不是单词字符,比如,”-cassiel-lee-transform “。function camelize(str) { return str.replace(/[-_\s]+(.)?/g, function(match, c) { return c ? c.toUpperCase() : ""; }); } console.log(camelize("-cassiel-lee-transform")); // => CassielLeeTransform
- 驼峰化
正则表达式回溯法原理
出现回溯的原因还是在于正则引擎:JS 采用的正则引擎是 NFA ,其匹配的过程就是吃入字符之后尝试匹配,如果通过,再吃入尝试;如果不通过,就吐出,回到上一个状态,因为同一个字符串在正则中可能存在一种状态不同转化路径,这时正则引擎就换一个转化状态进行尝试,如果通过,则继续吃入字符,否则继续吐出字符,回到再上一个状态。这种尝试不成功就返回上一状态的过程,我们称为”回溯”。正则匹配的性能好坏,就看回溯的情况,回溯越多,性能越差。
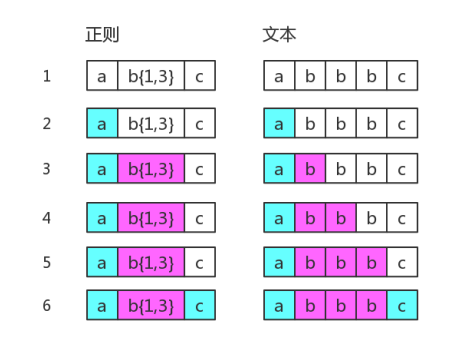
没有回溯的匹配
假设正则表达式/ab{1,3}c/,其中子表达式b{1,3}表示 “b” 字符连续出现 1 到 3 次。其可视化形式为: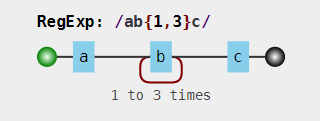
有回溯的匹配
当目标字符串是 “abbc” 时,中间就有回溯: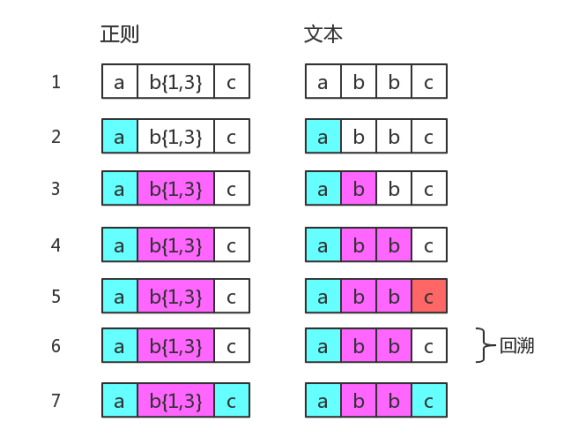
图中第 5 步有红颜色,表示匹配不成功。此时b{1,3}已经匹配到了 2 个字符 “b”,准备尝试第三个时,结果发现接下来的字符是 “c”。那么就认为b{1,3}就已经匹配完毕。然后状态又回到之前的状态(即第 6 步与第 4 步一样),最后再用子表达 c 去匹配字符 “c”。当然,此时整个表达式匹配成功了。图中的第 6 步,就是“回溯”。
再举一个例子:正则表达式是:/".*"/,目标字符串是:"abc"de,则匹配过程如下图所示。图中省略了尝试匹配双引号失败的过程。可以看出.*是非常影响效率的。为了减少一些不必要的回溯,可以把正则修改为/"[^"]"/。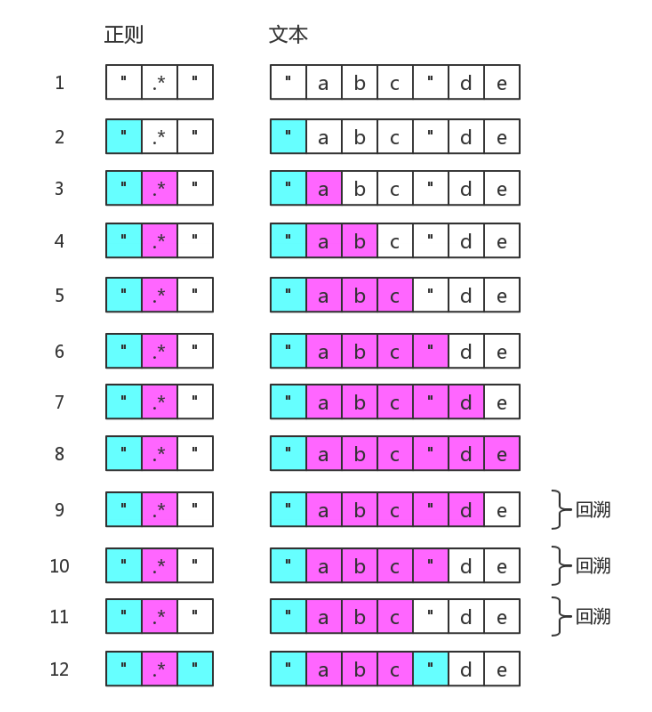
常见的回溯形式
从上面的描述过程中可以看出正则匹配的过程本质上就是深度优先搜索算法,当路走不通时,就会回退一步或者是若干步,然后换一条路继续走,其中回退的过程就是“回溯”。也就是说在正则表达式尝试匹配失败时,接下来的一步通常就是回溯。一般来说,容易产生回溯的情况如下:贪婪量词
例如:
上述例子是和贪婪量词有关的,即console.log("567".match(/(\d{1,3})(7)/)); // => [ '567', '56', '7', index: 0, input: '567', groups: undefined ]\d{1,3},因为其是贪婪的,尝试可能的顺序是从多往少的方向去尝试。也就是说\d{1,3}在匹配时,首先会尝试匹配 3 个数字,然后再看整个正则是否能匹配。不能匹配时,则吐出一个数字,即在 2 个数字的基础上,再继续尝试。如果还不行,再吐出一个,再试。如果还不行呢?只能说明匹配失败了。虽然局部匹配是贪婪的,但也要满足整体能正确匹配。如果当多个贪婪量词挨着存在,并相互有冲突时,会看匹配顺序,深度优先搜索。例如:const string = "567"; const regex = /(\d{1,3})(\d{1,3})/; console.log(string.match(regex)); // => [ '567', '56', '7', index: 0, input: '567', groups: undefined ]惰性量词
惰性量词就是在贪婪量词后面加个问号。表示尽可能少的匹配。虽然惰性量词会尽可能少的匹配,但是有些时候也会发生回溯,这种情况通常是为了整体匹配使得惰性量词匹配到的不是最少的数量。如下例中,正则表达式是/^(\d{1,3}?)(\d{1,3})$/,当目标字符串是”5678”是,刚好满足惰性量词\d{1,3}?匹配 1 个数字,贪婪量词\d{1,3}匹配 3 个数字,所以不会发生回溯。而当目标字符串是”12345”的时候。为了整体匹配,\d{1,3}?匹配到的并不只是一个数字,而是”12”两个数字。在这个匹配过程中会有回溯发生,匹配情况如下图:// 无回溯 const string = "5678"; const regex = /^(\d{1,3}?)(\d{1,3})$/; console.log(string.match(regex)); // => [ '5678', '5', '678', index: 0, input: '5678', groups: undefined ] // 回溯 const string1 = "12345"; console.log(string1.match(regex)); // => [ '12345', '12', '345', index: 0, input: '12345', groups: undefined ]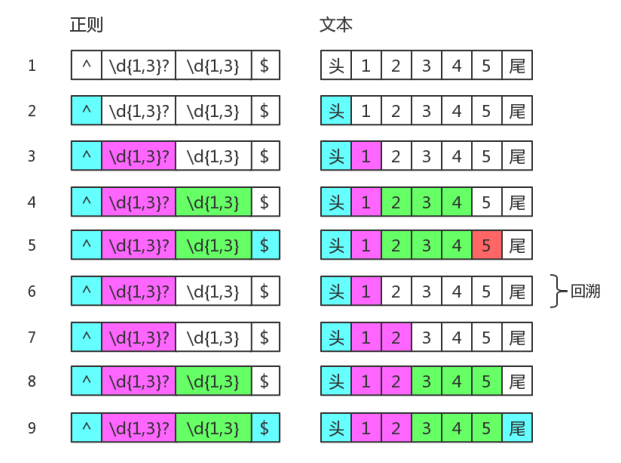
分支结构
前面说过分支也是惰性的,比如/biubiu|biubiubiu/,去匹配字符串 “biubiubiu”,得到的结果是 “biubiu”,因为分支会一个一个尝试,如果前面的满足了,后面就不会再试了。但是如果一个分支整体不匹配,则会继续尝试剩下分支,也可以看成一种回溯。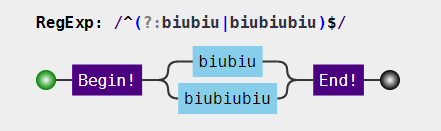
const string1 = "biubiu"; const string2 = "biubiubiu"; const regex = /^(?:biubiu|biubiubiu)$/; // 无回溯 console.log(string1.match(regex)); // 有回溯 console.log(string2.match(regex)); // => [ 'biubiu', index: 0, input: 'biubiu', groups: undefined ] // => [ 'biubiubiu', index: 0, input: 'biubiubiu', groups: undefined ]
正则表达式的拆分
结构和操作符
在正则表达式中,操作符都体现在结构中,即由特殊字符和普通字符所代表的一个个特殊整体。JavaScript 正则表达式中的结构有:字符字面量、字符组、量词、锚、分组、选择分支、反向引用。具体含义以及涉及到的操作符如下:
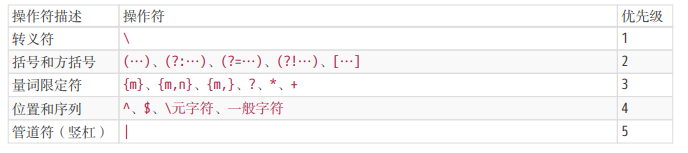
上述操作符的优先级从上至下,由高到低。举一个例子,/ab?(c|de*)+|fg/,其可视化形式: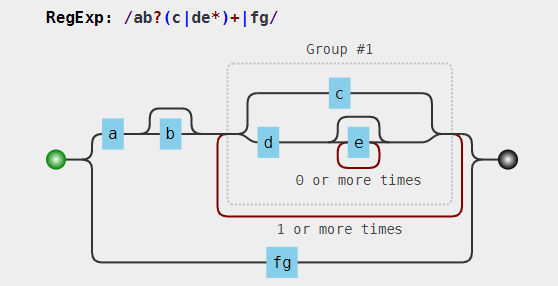
分析:首先由于括号的存在,所以,(c|de*)是一个整体结构。而在(c|de*)中 e 的后面有一个量词 ,因此 e 是一个整体结构。又因为分支结构 | 优先级最低,因此 c 是一个整体、而de*是另一个整体。同理,整个正则分成了 a、b?、(…)+、f、g。而由于分支的原因,又可以分成ab?(c|de*)+和fg这两部分。注意要点
字符串整体匹配
因为是要匹配整个字符串,我们经常会在正则前后中加上锚^和\$。比如要匹配目标字符串 “abc” 或者 “bcd” 时,如果一不小心,就会写成/^abc|bcd$/,事实上它匹配的模式是如下图,这是因为位置字符和一般字符的优先级要比分支结构要高,所以上述正则表达拆分开是^abc和bcd$两个部分。正确的表达式应该是/^(abc|bcd)$/,因为括号的优先级比位置和一般字符优先级高,所以括号中的内容是一个整体。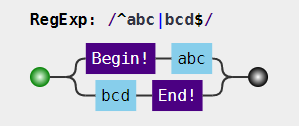
量词连缀问题
假如要匹配一个字符串其长度是 3 的倍数,且其中只能出现 a、b、c 这三个字符。这个问题,很容易想当然的写成:/^[abc]{3}+$/,咋一看这样写没毛病,但是实际上在可视化的时候会报错。正确的写法应该是:/^([abc]{3})+$/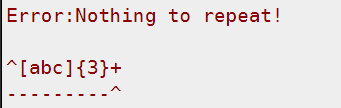
元字符转义问题
所谓元字符就是有特殊含义的字符。所有结构里涉及到的元字符有:^、$、.、*、+、?、|、\、/、(、)、[、]、{、}、=、!、:、-,当要对上述元字符本身进行匹配的时候,需要用转义符\进行转义。
注意:如果要匹配\本身那也需要进行转义。
当字符组中含有跟字符组相关的元字符时(例如,[、]、^、-),则需要在可能会引起歧义的地方进行转义。例如开头的^必须转义,不然会把整个字符组,看成反义字符组。其他符号如=、!、:、-, 等符号,只要不在特殊结构中,并不需要转义。至于剩下的^、$、.、*、+、?、|、\、/等字符,只要不在字符组内,都需要转义的。
案例分析
匹配 IPV4 地址/^((0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])\.){3}(0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])$/
分析:- 整个表达式的结构为
((...)\.){3}(...),其中前后两个(...)的结构是一样的,假设将其称为 P 结构,所以整个表达式的结构是:P结构.P结构.P结构.P结构。 - 再分析
(...)也就是 P 结构,(0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])是一个分支结构,一共有五个分支:0{0,2}\d,匹配一位数,包括 “0” 补齐的。比如,”5”、”05”、”005”;0?\d{2},匹配匹配两位数,包括 “0” 补齐的;1\d{2},匹配 “100” 到 “199”;2[0-4]\d,匹配 “200” 到 “249”;25[0-5],匹配 “250” 到 “255”;
- 整个表达式的结构为
正则表达式的构建
平衡法则
构建正则有一点非常重要,需要做到下面几点的平衡:- 匹配预期的字符串
- 不匹配非预期的字符串
- 可读性和可维护性,可以将复杂正则拆分成多个小正则
- 效率
准确性
准确性,就是能匹配预期的目标,并且不匹配非预期的目标。所以在写正则表达式的时候,需要先知道预期目标的组成规则。
例如:匹配浮点数1.23、+1.23、-1.23、10、+10、-10、.2、+.2、-.2。可以看出正则分为三个部分:符号部分:[+-],整数部分:\d+,小数部分:\.\d+。但是并不是每个部分都会出现,所以可以写出第一版表达式/^[+-]?(\d+)?(\.\d+)?$。
看似很容易就写出来了,但是这个正则会连空字符串""也能匹配到。因此可以将目标数据分为1.23、+1.23、-1.23、10、+10、-10、.2、+.2、-.2三类,然后对每一类提取正则表达式,因为这三类是或的关系,所以提取公共部分后得到:/^[+-]?(\d+\.\d+|\d+|\.\d+)$/。优化
正则表达式的运行通常分为五个阶段:1、编译;2、设定起始位置;3、尝试匹配;4、匹配失败的话,从下一位开始继续第 3 步;5、最终结果:匹配成功或失败。匹配的效率问题,主要出现在第 3 阶段和第 4 阶段。所以通常也从这两个方面进行优化。常见的优化手法如下:- 使用具体型字符组来代替通配符,来消除回溯
例如:匹配字符串abc"123"efg中的"123",如果正则用的是:/".*"/,因为是贪婪匹配,所以回匹配到最后一个字符是才发现匹配错误,此时需要回溯 4 次才能匹配成功;若正则采用的是:/".*?"/,此时是惰性匹配,*会优先匹配 0 次后发现后面字符无法继续匹配,此时需要回溯 2 次才能匹配成功;所以,最好的办法是采用/"[^"]*",此时不需要回溯。其可视化形式为: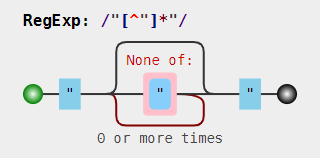
- 使用非捕获型分组
因为括号的作用之一是,可以捕获分组和分支里的数据。那么就需要内存来保存它们。所以当我们不需要使用分组引用和反向引用的时候最好使用非捕获分组来减少内存的占用。 - 独立出确定字符
例如:/a+/可以用/aa*/来代替,这样在匹配的时候可以加速判断是否成功或失败。 - 提取分支公共部分
例如:/this|that/修改成/th(?:is|at)/,这样做可以减少匹配过程中可消除的重复。 - 减少分支的数量,缩小它们的范围
例如:/red|read/可以修改成/rea?d/。但是分支和量词产生的回溯的成本是不一样的。这样优化后,可能会造成可读性降低。
- 使用具体型字符组来代替通配符,来消除回溯
正则表达式编程
正则表达式的四种操作
正则表达式是匹配模式,不管如何使用正则表达式,万变不离其宗,都需要先“匹配”。所谓匹配,就是看目标字符串里是否有满足匹配的子串。因此,“匹配”的本质就是“查找”。
验证
“验证”就是判断正则表达式有没有匹配,是不是匹配上,是一种判断是否的操作。
比如:使用 test 判断一个字符串中是否有数字。const regex = /\d/; const string = "abc123"; console.log(regex.test(string)); // true切分
匹配到字符串,我们就可以进行一些操作,比如切分。“切分”,就是把目标字符串,切成一段一段的。通常可以结合 JavaScript 中的 split 函数进行切分。
例如:切分出不同日期格式中的数字const regex = /\D/; console.log("2017/06/26".split(regex)); console.log("2017.06.26".split(regex)); console.log("2017-06-26".split(regex)); // => [ '2017', '06', '26' ]提取
虽然整体匹配上了,但有时需要提取部分匹配的数据。
例如:提取日期中的年月日const regex = /^(\d{4})\D(\d{2})\D(\d{2})$/; const string = "2019-12-31"; console.log(string.match(regex)); // ['2019-12-31','2019','12','31',index: 0,input: '2019-12-31',groups: undefined]替换
找,往往不是目的,通常下一步是为了替换。在 JavaScript 中,使用 replace 进行替换。
相关 API 注意事项
正则操作相关方法:
- String#search
- String#split
- String#match
- String#replace
- RegExp#test
- RegExp#exec
这些方法的详细用法可以参考《JavaScript 权威指南》的第三部分。
search 和 match 的参数问题
所有字符串实例的那 4 个方法参数都支持正则和字符串。但 search 和 match,会把字符串转换为正则。match 返回结果的格式问题
match 返回结果的格式,与正则对象是否有修饰符 g 有关。没有 g,返回的是标准匹配格式,即,数组的第一个元素是整体匹配的内容,接下来是分组捕获的内容,然后是整体匹配的第一个下标,最后是输入的目标字符串。有 g,返回的是所有匹配的内容。当没有匹配时,不管有无 g,都返回 null。exec 比 match 更强大
当正则没有 g 时,使用 match 返回的信息比较多。但是有 g 后,就没有关键的信息 index 了。而 exec 方法就能解决这个问题,它能接着上一次匹配后继续匹配。修饰符 g,对 exex 和 test 有不同的影响
正则实例有一个 lastIndex 属性,表示尝试匹配时,从字符串的 lastIndex 位开始去匹配。而字符串的四个方法(search、split、match、replace),每次匹配时,都是从 0 开始的,即 lastIndex 属性始终不变。而正则实例的两个方法 exec、test,当有修饰符 g 时,每一次匹配完成后,都会修改 lastIndex。但是如果没有 g 的时候,并不会修改 lastIndex 的值。test 整体匹配时需要使用 ^ 和 $
因为 test 是看目标字符串中是否有子串匹配正则,即有字符串中部分匹配正则即可。console.log(/123/.test("12345")); // => true console.log(/^123$/.test("12345")); // => false console.log(/^123$/.test("123")); // => truesplit 相关
- split 可以有第二个参数,表示结果数组的最大长度。
- 正则使用分组时,结果数组中是包含分隔符的。
构造函数
在生成正则表达式的时候,一般不推荐使用构造函数生成正则,而应该优先使用字面量。因为用构造函数会多写很多 \。const regex1 = /\d{4}(-|\.|\/)\d{2}\1\d{2}/g; const regex2 = new RegExp("\\d{4}(-|\\.|\\/)\\d{2}\\1\\d{2}", "g");修饰符
ES5 中的修饰符:

正则实例对象属性
正则实例对象的属性除了 global、ingnoreCase、multiline、lastIndex 属性之外,还有一个 source 属性。在构建动态的正则表达式时,可以通过查看该属性,来确认构建出的正则表达式。构造函数的静态属性
构造函数的静态属性基于所执行的最近一次正则操作而变化。除了是 $1,…,$9 之外,还有几个不太常用的属性(有兼容性问题):
正则表达式的拓展及安全性
拓展
前面的内容基于 ES5 的正则表达式,在 ES6 及后续版本中,又新增了一些正则的特性,例如:
ES6 增加了修饰符 u, y,u 字符用来正确处理大于\uFFFF 的 Unicode 字符。也就是说,可以正确处理四个字节的 UTF-16 编码。y 修饰符的作用与 g 修饰符类似,也是全局匹配,后一次匹配都从上一次匹配成功的下一个位置开始。不同之处在于,g 修饰符只要剩余位置中存在匹配就可,而 y 修饰符确保匹配必须从剩余的第一个位置开始。
const s = "aaa_aa_a"; const r1 = /a+/g; const r2 = /a+/y; r1.exec(s); // ["aaa"] r2.exec(s); // ["aaa"] r1.exec(s); // ["aa"] r2.exec(s); // nullES2018 增加了修饰符 s ,使得.可以匹配任意单个字符(包括行终止符)。
ES2018 支持具名组匹配及后行断言。
更多新特性可参考ES6 入门教程——正则的拓展
安全性
写得不好的正则表达式可能会导致正则表达式引擎耗费大量的时间在回溯上,达到输入长度的指数级!一个不太长的字符串(几十或几百),就能让正则引擎这辈子都跑不出匹配结果,从而导致拒绝服务攻击(Denial of Service)。因为是正则表达式导致的,缩写成 ReDoS(Regular expression Denial of Service),即正则表达式拒绝服务攻击。
检测工具:- SDL-Regex-Fuzzer,微软开发的 ReDoS 检测工具,但已经不再维护了。
- ReScue,2018 年南京大学一篇关于 ReDoS 的论文使用的工具,已开源。
结语
这不是第一次看有关正则的知识,只是之前每次看的知识点都比较基础也不全面,这一次算是从头到尾又过了一遍正则的知识。感觉受益匪浅,希望在今后的工作中再也不要被正则难倒!
最后我认为学习最重要还是:纸上得来终觉浅,觉知此事要躬行。
![React源码解读[一]](/medias/featureimages/8.jpg)
